Processing large files in Node.js can be a challenging task because the node process can become a bottleneck when working with such files. To tackle this problem, we need to introduce event handlers that allow us to keep pushing data into the pipeline and prevent blocking on any single operation.
The Challenge
Imagine you have a 10GB log file that you need to analyze for insights. However, reading the entire file into memory can cause your application to buckle under the weight and grind to a halt, consuming precious resources.

The Solution
To overcome this challenge, we can use chunks and streams to read data in bite-sized pieces, minimizing memory usage and keeping our application nimble. Think of this approach as savoring a delicious meal, course by course, instead of attempting to devour the entire feast at once.
Stream processing, along with careful chunk size management, allows us to handle large files efficiently without consuming excessive resources. Chunk Size controls the amount of data read from the file at a time. Adjusting this can fine-tune performance for different file sizes and processing needs.
Setting Chunk Size for readStream: stream.Readable:
- Using the highWaterMark Option:
In this example, the stream will read data in chunks of 64 KB, striking a balance between memory usage and processing efficiency. The optimal chunk size depends on your specific file size, processing tasks, and available memory.
const readStream = fs.createReadStream('large.file', { highWaterMark: 64 * 1024 }); // default - 64 KB chunks
- Manually Pausing and Resuming:
readStream.on('data', (chunk) => {
// Process chunk
readStream.pause(); // Pause after processing
// ... do something with the chunk ...
readStream.resume(); // Resume when ready for more data
});Additional Considerations:
- Experiment with different chunk sizes to find the optimal setting for your use case.
- Consider the nature of your processing tasks and available memory resources.
Event Handlers: The Orchestrators of Efficiency
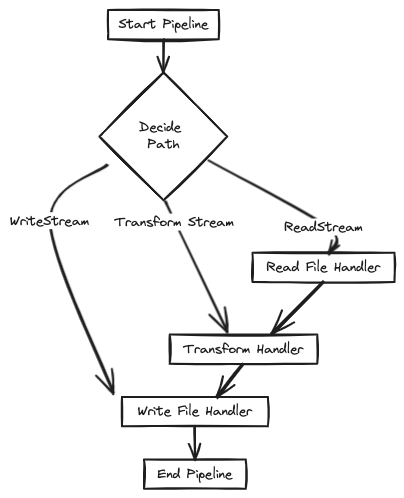
But reading chunks alone is not enough. We need a conductor, an event handler that dictates what to do with each data morsel. Event handlers act as loyal assistants, listening for specific events emitted by the stream and triggering our desired actions on each chunk. For example, an event may prompt us to analyze the chunk's contents, while another event signals the completion of the file, allowing us to perform cleanup tasks.
import * as stream from 'stream';
import * as util from 'util';
export interface Handler {
(chunk: any): Promise<void>;
}
export class StreamProcessor {
private readonly readStream: stream.Readable;
private readonly handlers: Handler[];
private readonly outStream: stream.Writable;
constructor(
readStream: stream.Readable,
handlers: Handler[],
outStream: stream.Writable
) {
this.readStream = readStream;
this.handlers = handlers;
this.outStream = outStream;
}
async processStream(): Promise<void> {
await util.promisify(stream.pipeline)(
this.readStream.data,
...this.handlers,
this.outStream
);
}
}
Conclusion
In this article, we have shown you how to use stream processing to process large files in Node.js. By using event handlers, we can keep pushing data into the pipeline and prevent blocking on any single operation. This approach allows us to process large files efficiently and without consuming excessive resources.
© This content was partially generated by IDX AI.